JavaScript Obfuscation: The Definitive Guide for 2025
January 28th, 2025 | By Jscrambler | 18 min read

The JavaScript Obfuscation Practical Guide 2025 provides a step-by-step approach to exploring key questions, namely:
What is an obfuscation code?
Why obfuscate JavaScript code?
What is JavaScript obfuscation, and how does it work?
What are the obfuscation techniques and metrics in JavaScript?
What is an example of JavaScript obfuscation?
Why isn't JS obfuscation frequently not enough to cover some use cases?
Familiarity with JavaScript and npm is a plus, but not necessary to dive into this guide. Let’s get into it!
Chapter 1: What is Obfuscation of Code?
Obfuscation of code is a technique used to transform plain, easy-to-read code into a new version that is deliberately hard to understand and reverse-engineer—both for humans and machines.
Think of obfuscation like this: you call a friend to schedule a coffee for later (remember when that was a thing?). A possible reply would be something like: “Hi! Sorry, I can’t do it today. I have to watch the kids. Same time tomorrow?”.
But let’s imagine that your friend decided to obfuscate this a bit, hitting you with a hearty “Good morrow. I offer thee the sincerest of apologies, but, alas, I can't doth t the present day. Haply tom'rrow, equal timeth? Has't to taketh careth of mine own children, I do. Sinc're apologies I offer thee. Fare thee well.”
Well, that was a mouthful. If you take a closer look at your friend’s Shakespearean reply, it’s clear that the whole thing is unnecessarily complicated. It takes a lot longer to decipher the meaning of the message, and there are some redundancies. Plus, your friend added some irrelevant details. Sure, you can bear to decipher this nonsense once. But will you keep calling your friend if this becomes a permanent thing?
As silly of an example as this may seem, it includes the same reasoning as some techniques used in code obfuscation. In the next chapter, we’ll see real examples of obfuscation of code, and you’ll hopefully see the resemblance.
While (thankfully) there aren’t many real-life examples of obfuscation in human conversation, obfuscation of code has been around for a long time - there are references to “code obfuscation” in books dating back to 1972.
Obfuscation has been used in several different programming languages, notably C/C++ (there’s even a competition for obfuscating C code) and Perl. But there’s a language where obfuscation has gained tremendous popularity among developers and business owners alike: JavaScript.
Chapter 2: JavaScript Obfuscation
Why obfuscate JavaScript code?
JavaScript has quickly grown into the language of the web. It powers nearly every website in existence, and the rise of cross-platform JavaScript frameworks like React Native and Ionic allows developers to create mobile and desktop apps using a shared JS codebase.

With every single Fortune 500 company using JavaScript to develop their apps, today we see JS powering critical applications in various fields like mobile banking, e-commerce, and streaming services.
This brings us to the main question: Why obfuscate JavaScript code?
JavaScript is an interpreted language, so client-side JavaScript requires an interpreter in the browser to read it, interpret it, and run it. This also means that anyone can use a browser debugger to easily go through the JS code and read or modify it at will.
In the example below, you can see someone easily accessing the code logic behind a virtual keyboard where a bank's clients type their passwords.
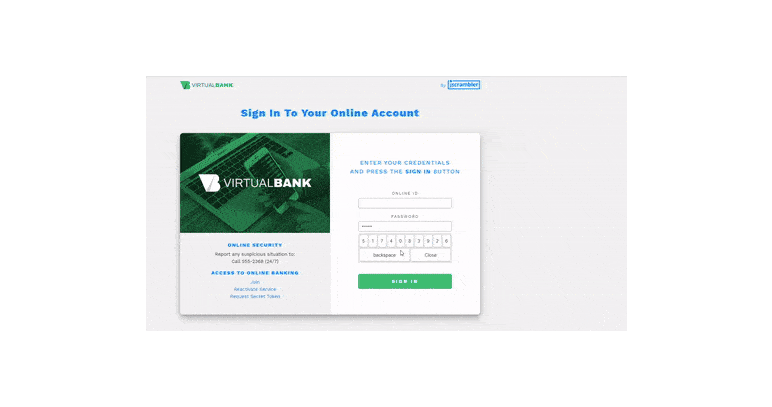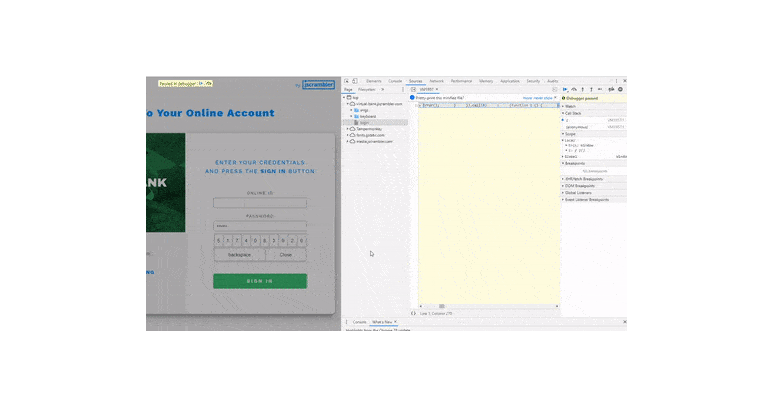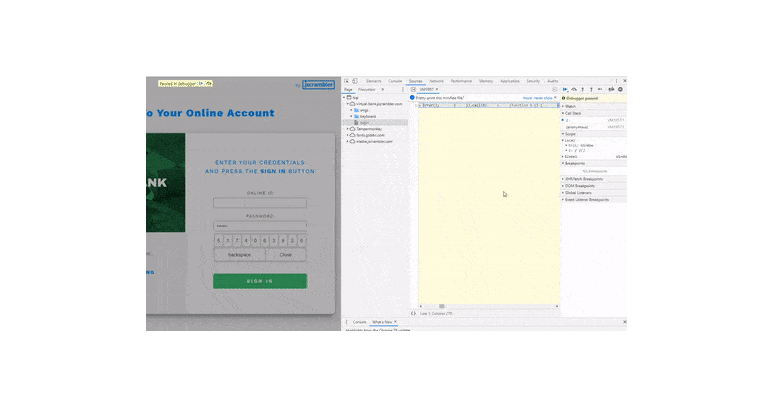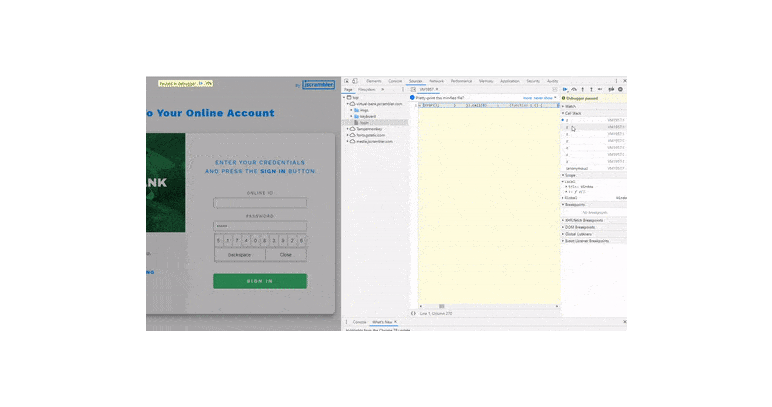
With such easy access to client-side JavaScript code, it’s almost effortless for an attacker to take advantage of this security weakness and target any unprotected code.
All of this should seem trivial when we’re talking about a simple web application. But companies—notably, the enterprise and Fortune 500—are frequently storing important business logic on the client side of their apps.
If you understand the basics of application security, you know that code secrets should always be kept on trusted execution environments like the backend server. But this is one of those cases where practice takes precedence over theory. When companies store this important logic on the client side, they typically do so because they can’t feasibly keep it on the server side.
A common reason for this is when there’s no backend in the first place, as in the case of some mobile applications. Another example is when there’s some code that’s related to the user experience (like an analytics algorithm) that must run on the client side. Still, the most common reason is performance. Server calls take time, and when you have a service where performance is crucial—like a streaming platform or an HTML5 game—storing all the JavaScript on the server is not an option.
Whatever the case, companies usually don’t want to expose their proprietary logic. And they definitely never want to expose code secrets. Especially when their competitors can reverse-engineer the code and copy proprietary algorithms.
Besides intellectual property theft, client-side JavaScript can also be targeted in more sophisticated attacks such as automated abuse, piracy, cheating, and data exfiltration (learn more about JavaScript protection and in-depth security).
It’s no wonder that information security standards like ISO 27001 make statements such as:
“Program source code can be vulnerable to attack if not adequately protected and can provide an attacker with a good means to compromise systems in an often covert manner. If the source code is central to the business success its loss can also destroy the business value quickly too.”
And OWASP (Open Web Application Security Project) clearly reinforces this recommendation in their Mobile Top 10 Security Risks guide:
“In order to prevent effective reverse engineering, you must use an obfuscation tool.”
What is JavaScript obfuscation?
JavaScript obfuscation is a series of code transformations that turn plain, easy-to-read JS code into a modified version that is extremely hard to understand and reverse-engineer.
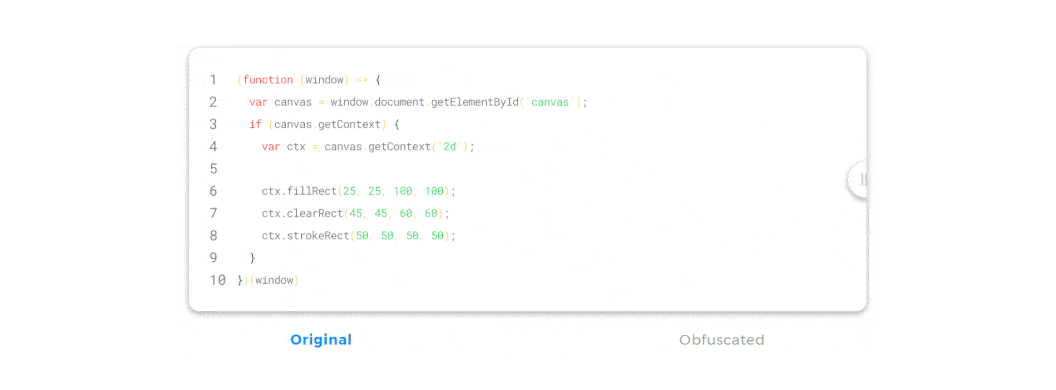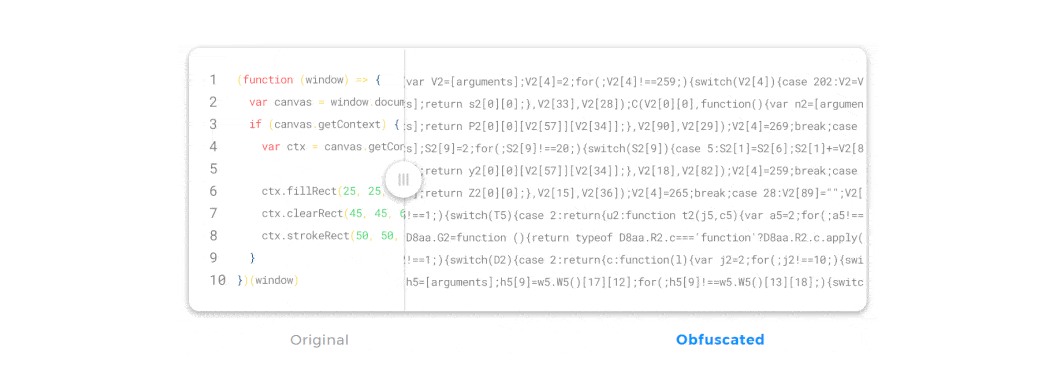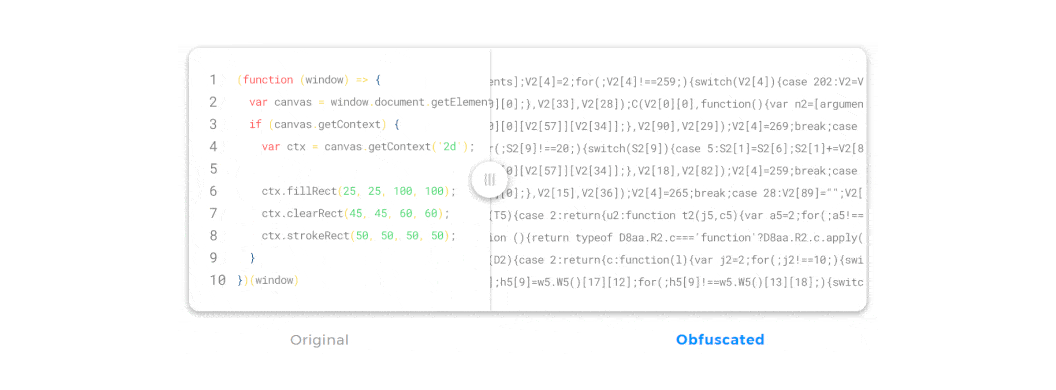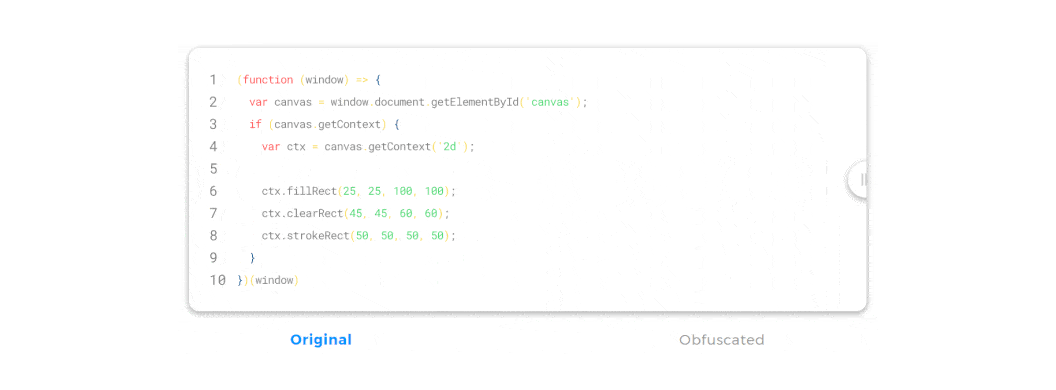
Unlike encryption, where you must supply a password used for decryption, there’s no decryption key in JavaScript obfuscation. If you encrypt JavaScript on the client side, that would be a pointless effort—if we had a decryption key we needed to supply to the browser, that key could become compromised and the code could be easily accessed.
So, with obfuscation, the browser can access, read, and interpret the obfuscated JavaScript code just as easily as the original, un-obfuscated code. And even though the obfuscated code looks completely different, it will generate precisely the same output in the browser.
JavaScript obfuscation is often confused with other techniques like minification, optimization, and compression. Let’s quickly look at the differences between them.
JavaScript obfuscation vs minification, optimization, and compression
Code minifiers remove unnecessary characters in the code (whitespaces, newlines, smaller identifiers, etc.), minimizing the size of the code—but they don’t protect the source code.
Code optimizers are mostly used to improve code performance (speed and memory use of the app). Sometimes they can also make the code harder to read, but this provides no protection (as we’ll see later on).
Code compressors and packers reduce the code size using encoding and packing techniques, but they also don’t protect the source code.
Another common misconception is that if you already use SAST or DAST to find vulnerabilities in your JavaScript code and fix them, this solves all your code problems. While SAST or DAST are useful to fix vulnerabilities, they don’t prevent code tampering and reverse engineering, as vulnerabilities are not required to do that. As such, it’s advisable to use SAST and DAST alongside JavaScript source code protection.
JavaScript Obfuscation Techniques & Targets
Now that it’s clear what JS obfuscation is in a broader sense, let’s get a bit more technical. Let's explore what it specifically does to the source code.
The main purpose of obfuscation is to hide JavaScript and parts of the code that would be potentially targeted by attackers or competitors. Thus, it’s easy to understand why you would want to obfuscate any data in the code. By concealing things like variables, objects, and strings, you will make it harder for anyone to understand what type of data lies within the code.
Sidenote
Relying on obfuscation alone to protect sensitive data in your code is a bad practice and the reason why you will probably hear someone say “Obscurity isn’t security”.
Depending on your use case, you should always use obfuscation in addition to good security practices. Think of it like this: If you wanted to keep a pile of cash secure, you’d probably put it in a safe. But instead of leaving that safe completely exposed on your front porch, you’d probably also hide it somewhere to minimize the likelihood of someone finding it and trying to break it open.
But concealing data is just one of several dimensions of JS obfuscation. Strong obfuscation will also obfuscate the layout and program control flow, as well as include several optimization techniques. Typically, it will target:
Identifiers;
Booleans;
Functions;
Numbers;
Predicates;
Regular expressions;
Statements; and
Program control flow.
Common JavaScript Obfuscation Techniques
The most common JavaScript obfuscation techniques are reordering, encoding, splitting, renaming, and logic concealing techniques.

Understanding each technique in depth is out of the scope of this guide, but their names are already pretty self-explanatory. If you’d like to learn more about each possible technique, check out this documentation about code integrity transformation assets.
However, Control-flow obfuscation is worthy of a deeper explanation, as it is an especially useful technique. It makes the program flow significantly harder to follow by removing the natural conditional constructs that make the code easier to read.
From a technical perspective, it splits all the source code's basic blocks — such as function body, loops, and conditional branches — and puts them all inside a single infinite loop with a switch statement that controls the program flow. It can also include:
Clones (semantically equivalent copies of basic blocks that can be executed interchangeably with their original basic blocks);
Dead clones (dummy copies of basic blocks that are never executed, but mimic and can be confused with the code that will be executed); and
Opaque steps (which obfuscate the switching variable, making it harder to understand what's the next switch case that’ll be executed).
The combination of these techniques adds to the overall complexity of the obfuscated code.
Another noteworthy approach to obfuscation is the use of polymorphism.
Polymorphic JavaScript obfuscation is a unique technique used by Jscrambler that ensures that every new code obfuscation results in completely different code.
Let's look at an example:
Imagine you are deploying obfuscated code builds once per week. Attackers may start trying to de-obfuscate the code as soon as you ship a new version.
Assuming they have made some progress before you release a new build, if the obfuscated code of the new build is similar to the previous one, attackers can leverage most of their progress to continue their reverse engineering. With polymorphic obfuscation, the new build is completely different, which means that most (if not all) of the previous de-obfuscation progress becomes useless.
JavaScript Obfuscation Example
It's time to put the theory on hold for now. Let’s jump right into an actual JavaScript obfuscation example.
Consider the code snippet below, which is an algorithm that is used to recommend products to the shoppers of an e-commerce website. It generates a list of product recommendations for a given customer based on that customer’s history of previous purchases.
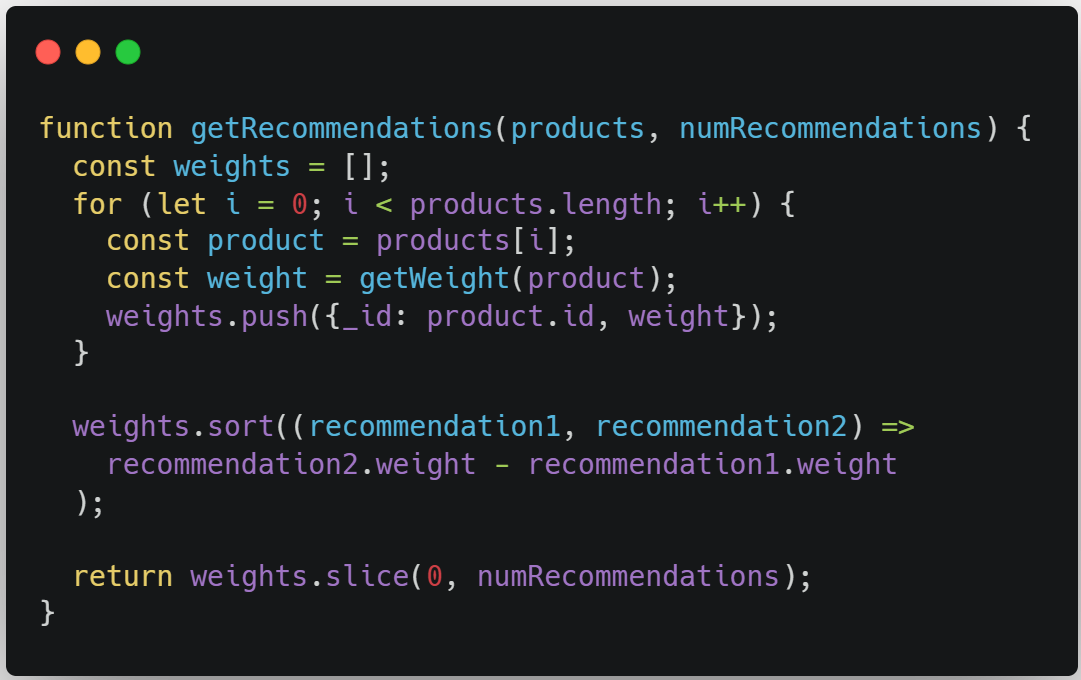
This seems like pretty ordinary code. However, imagine that this is a proprietary algorithm developed by the company that is being used as an example. If we were a competitor visiting their website, we could quickly find this code and do what we wanted with it.
As the owners of this code, we understand this risk and want to protect it. Before we get into actual JS obfuscation, let’s see what minification would do to the code.

At first glance, you’d say it’s harder to read the code. But it just takes a second to realize that all our functions, objects, and variables are there in plain sight. Again, minification doesn’t offer any sort of code protection.
Let’s now see what the code looks like after we add a single obfuscation technique.
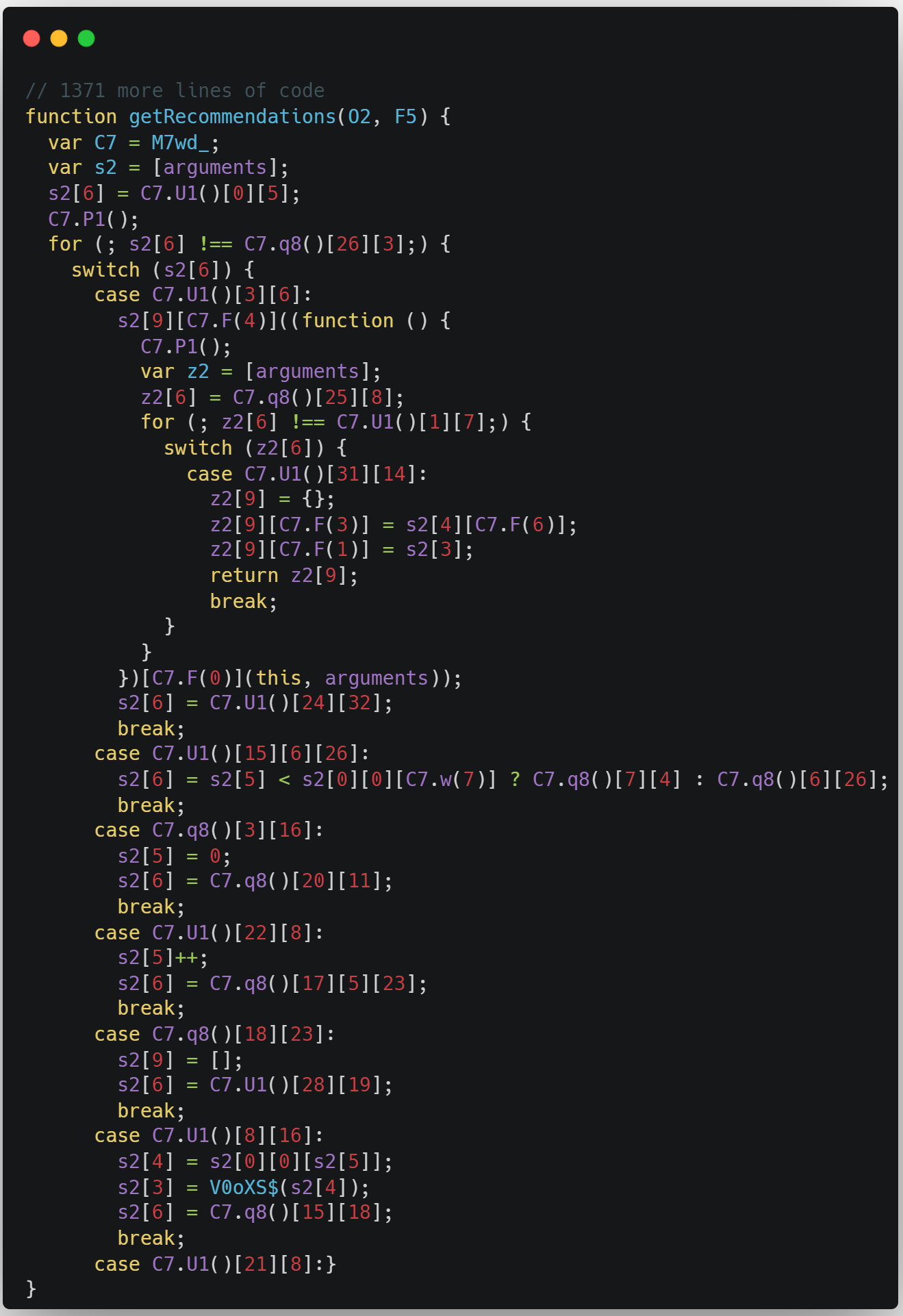
First off, this doesn’t even seem like recognizable JavaScript code. It has been obfuscated with something called control-flow flattening—a unique Jscrambler transformation that flattens the program flow and conceals every single natural conditional construct that would otherwise make the code easier to read.
Sidenote
If you want to test this obfuscation transformation in your code to see what the output looks like, you just need to create a free Jscrambler account.
The snippet above shows the first few lines of code, but the whole thing is almost 700 lines long. And if we run this code, the browser will run it just like the original thing.
Now let's look at an example of extreme obfuscation:
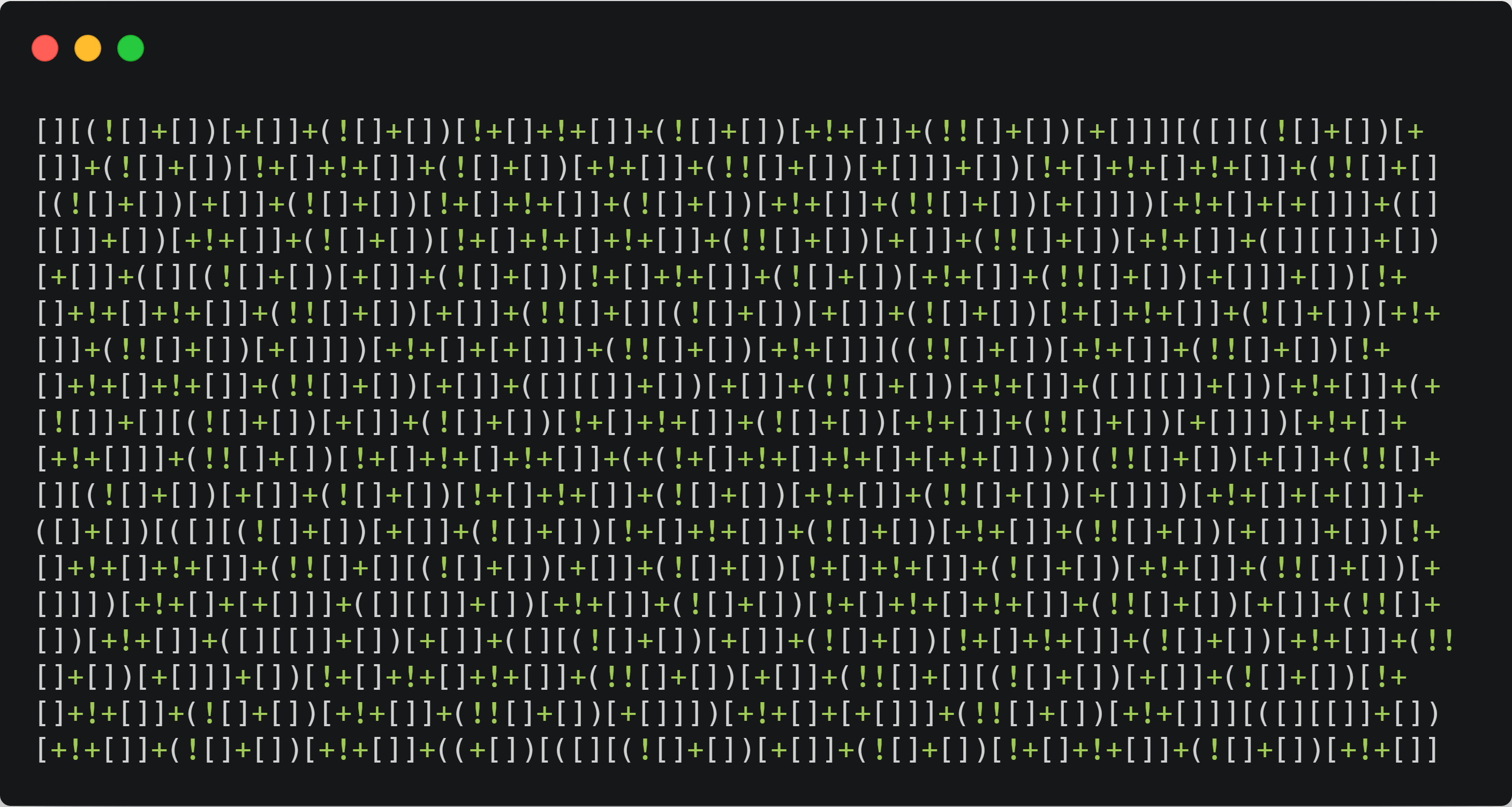
This is a piece of code that has non-alphanumeric obfuscation, which you don’t often find in the wild. To the human eye, this seems impossible to reverse engineer. But if we ran this code through an automated reverse-engineering tool, we would get the original code almost immediately.
This seemingly extreme obfuscation is, in fact, a great example of what weak obfuscation can look like.
How can we distinguish between weak and strong obfuscation? First, we need to understand the obfuscation metrics.
JS Obfuscation Metrics
One of the clearest interpretations of JS obfuscation metrics is provided by Collberg et al. in their paper “A Taxonomy of Obfuscating Transformations”.
As these researchers put it, there are three key metrics: potency, resilience, and cost.
Metric 1: Potency
Potency is a metric that answers the question “To what degree is a human reader confused?”.
Looking back at our three previous examples, we can confidently say that example #1 (minification) has low potency, while example #2 has high potency and example #3 has extremely high potency.
You might be wondering, "How do I calculate the potency metric?". Well, potency is typically measured using software complexity metrics such as Halstead's Metrics. So, you typically won’t be calculating potency yourself.
That being said, there are some specific characteristics of the transformation that you can use to more easily evaluate its potency. So, a high-potency transformation typically:
hides constants and names;
makes it difficult to understand the order in which the code is executed;
makes it difficult to understand what the relevant code is;
increases overall program size and introduces new classes and methods;
introduces new predicates and rewrites the conditional and looping constructs;
increases long-range variable dependencies.
However, one key mistake when evaluating obfuscated JavaScript code is only considering its potency. And as we saw before, a high-potency transformation can be very easy to defeat. That’s why we must also consider another metric: resilience.
Metric 2: Resilience
The resilience metric answers the question “How well are automatic deobfuscation attacks resisted?”.
For example, we can add an if statement that introduces a dummy variable into our code. It may take a while for a human to identify the code as dummy code, but a deobfuscator would immediately remove the statement.
This is why resilience is calculated by considering two different aspects:
the amount of time required to develop a deobfuscator capable of reverting a transformation's result;
the required execution time and space by a deobfuscator to effectively revert the transformation.
This is the metric where most obfuscation tools fail, especially free JS obfuscators. They may output what looks like highly obfuscated code, but it’s typically quite simple to de-obfuscate it using readily available tools. When comparing different obfuscation results, we can’t simply trust our own eyes and perception.
Jscrambler’s transformations, however, are built to achieve maximum resilience whenever possible.
Specifically, Jscrambler includes a code-hardening feature that is built into every code obfuscation. This feature provides the code with guaranteed, up-to-date resilience against all automated reverse engineering tools and techniques.
When these tools attempt to reverse code protected by Jscrambler, they will time out or hang, forcing attackers to go manual and face the dreaded high-potency transformations by hand.
Metric 3: Cost
Finally, we have the cost metric, which represents the impact of a transformation on the execution time of a transformed application as well as the impact on the application's file size.
This is important because you wouldn’t want your application performance to be ruined due to obfuscation, especially when you have a client-facing app and could be losing money if the app starts running slowly.
A good obfuscation tool should always provide specific features to minimize performance hits and also allow you to fine-tune the transformations throughout your code. This is yet another shortcoming of free JavaScript obfuscators, which typically provide little to no capability to fine-tune the protection.
In contrast, using Jscrambler, you’ll find several features that automatically fine-tune the protection to maximize performance, such as Profiling and App Classification.
Understanding these three obfuscation metrics is crucial to ensuring that your code is actually protected and doesn’t just look like it.
Chapter 3: Obfuscation & The SDLC
JavaScript obfuscation shouldn’t result in process overhead or overcomplicate your SDLC. To make sure that doesn’t happen, it’s critical to address two dimensions: compatibility and integration.
Compatibility of Obfuscated JavaScript Code
When it comes to compatibility, first there’s the matter of understanding if your source code is compatible with a specific obfuscation tool.
Some JS obfuscators lack compatibility with some ECMAScript versions and may require you to transpile the code as an extra step before protecting it. More frequently, they may lack compatibility with certain JS libraries and frameworks, requiring substantial changes to enable code protection.
Another important aspect is the compatibility of the obfuscated code. Going back to our original definition of JavaScript obfuscation, it is “used to transform (...) code”. While your obfuscated code should always run just like the original code, obfuscation can result in some compatibility changes, namely with specific browser versions.
As an enterprise product, Jscrambler ensures compatibility with all ECMAScript versions and provides features like Browser Compatibility to give visibility and control over the compatibility of the protected code. So, you can always ensure that the protected code will be compatible with the target browser versions. Plus, it ensures compatibility with all the main JS libraries and frameworks.
Obfuscation, CI/CD Integration, and Making Engineers Happy
If you want to ensure that all your app deployments are obfuscated, you will likely want to automate this process. Here, it’s especially important to consider what JavaScript frameworks you’re using and how your build process is structured.
As mentioned before, several obfuscators offer very limited compatibility with JavaScript frameworks, especially with React Native and Ionic. So, they will typically fail to obfuscate the code altogether.
In the case of Jscrambler, the obfuscation process is done at build time and is fully compatible with every main JavaScript framework.
Jscrambler can be easily integrated into the build process of React, Angular, Vue, Node.js, React Native, Ionic, NativeScript, and many other frameworks. Integrating Jscrambler into your CI/CD pipeline is simple, and there are even integrations for specific build processes: You just need to call the Jscrambler API and get a protected version of your application. This protected version is the one you should deploy.

A smooth CI/CD integration will certainly put a smile on your engineers' faces, but there’s still another “quality of life” feature that is especially relevant when it comes to obfuscation.
After seeing the previous examples of obfuscated code, you might have wondered “How do I debug this protected code?”. Since the goal of obfuscation is to make it harder to go through the code, it may make the lives of your developers a living nightmare when they have to debug a bug in production. Hence the importance of source maps.
While many obfuscation tools do not provide comprehensive source maps, Jscrambler Source Maps enable easily mapping the obfuscated code back to its original source code—both through the web app and through the Jscrambler CLI.
Support and Trust
As with all things related to security, obfuscation is a high-stakes process.
Just like using a weak JS obfuscator can provide a false and dangerous sense of security, misconfiguring any obfuscation tool can result in serious problems that jeopardize the overall security and usability of the application.
So, if you’re not a JS obfuscation expert, how can you navigate this configuration and avoid any pitfalls?
To prevent being blindsided by poor configuration, make sure that you’re using an obfuscation tool that provides comprehensive documentation along with priority support. Every app is different, and obfuscation is surely not a one-size-fits-all solution. By counting on a dedicated support team, you can more easily fine-tune the obfuscation to match your specific use case and avoid common pitfalls that can degrade the usability of your app.
There’s no way around it: Security is trust.
Just like you wouldn’t give your source code (especially if it contains sensitive information) to any random person, you likely won’t want to blindly trust any JS obfuscator with it.
A particular thing about obfuscation is that it’s seriously difficult to vet the end result. There have been some cases where free obfuscators added malware/spyware to the source code before obfuscating it. It’s extremely important to exercise due diligence with the tool you’ll be using to avoid any unpleasant surprises.
Chapter 4: Beyond Obfuscation, JavaScript Protection
Usually, most guides on JavaScript obfuscation end right about here. But this bonus chapter is a must-read because it will explain why JS obfuscation is frequently not enough to cover some use cases.
Why isn't JS obfuscation frequently not enough to cover some use cases?
While obfuscation should provide a good way of preventing reverse-engineering and making it extremely difficult for anyone (including attackers) to understand, target, and potentially steal the logic of your app, more advanced threats like code tampering, data exfiltration, piracy, and automated abuse require advanced JavaScript protection.
JavaScript Protection: Environment Checks/Locks
One important type of JavaScript protection is the so-called environment checks or code locks. These allow locking the JavaScript code to only run in specific environments.
These environments typically include operating systems, browsers, domains, dates, or certain types of devices, like mobile phones that haven’t been rooted or jailbroken.
Each of these locks can help accomplish different requirements. For example, if you have an app that deals with very sensitive data or performs critical tasks, you can prevent it from running on rooted or jailbroken devices because these are more vulnerable to attacks. And if you want to enforce licensing agreements, you can deliver a product demo to a client and have that code locked to the client’s domain and automatically expire after a specific date.
Usually, whenever a lock violation occurs, the application will break. So, these locks can be especially useful against piracy and license violations. But there’s another type of JS protection that is very useful in almost every single use case: runtime protection.
JavaScript Protection: Runtime Protection
Attackers might be hard to dissuade with obfuscation alone. In certain types of attacks, such as data exfiltration and automated abuse, the potential gains of a successful attack may justify an extensive effort to reverse-engineer the code.
The most common first step in reverse engineering is to try to understand the logic of the obfuscated code by debugging it and experimenting with it at runtime to gradually understand portions of the code.
A methodical approach may eventually yield some results (which will greatly vary depending on the tool that was used to obfuscate the code and the usage of polymorphic obfuscation). Runtime protection can make this reverse engineering process much harder by preventing any type of debugging or tampering with the protected code.
From a technical perspective, this is achieved by scattering integrity checks and anti-debugging traps throughout the source code.
As a first step to understanding the logic of the protected code, attackers will normally use a debugger and perform a step-by-step inspection of the code. If the code has been instrumented with anti-debugging traps, whenever attackers attempt to use a debugger, the traps will be triggered, breaking the application on purpose and getting attackers stuck in an infinite debugger loop.
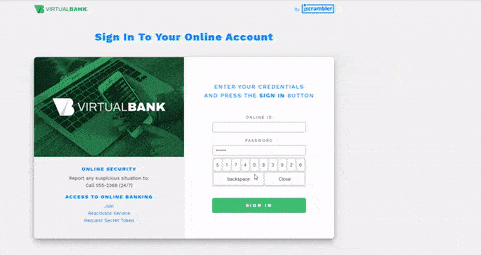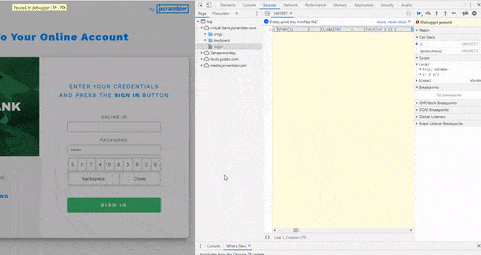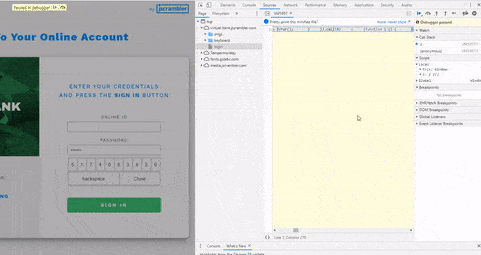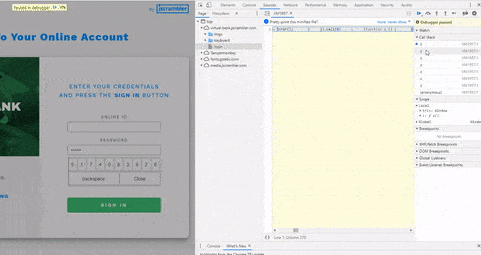
When attackers cannot inspect the code dynamically by debugging it, their next best step is to download the code to statically analyze and modify it. Successfully modifying code is an essential step for anyone reversing or tampering with an application. However, if the source code contains integrity checks, once any changes are made (like simply changing a single character), these checks will be triggered, also breaking the code to prevent the attack from being successful.
As you may expect, all these locks and checks will frustrate attackers, especially when they are coupled with additional countermeasures.
JavaScript Protection: Countermeasures
Usually, whenever there’s a violation of a code lock or when anti-debugging traps or integrity checks are triggered, the default response is to derail the app execution to contain a possible threat.
However, breaking the app is only one example of several possible countermeasures. Other possibilities include:
redirecting attackers to another page, to make them lose all progress;
deleting the cookies, namely as a countermeasure to thwart scraping attacks;
sending a real-time notification to a dashboard with the full details of the incident;
destroying the environment of the attacker, by crashing the memory, destroying the session, and destroying objects;
triggering a custom callback function for complete flexibility and control over the intended reaction.
This level of customization can definitely help fine-tune the overall code protection to match your specific use case.
Security In-Depth
While JavaScript obfuscation is often the entry point for those looking for some degree of source code protection, the bottom line is that obfuscation is usually a means to an end.
While developing your application’s threat model, it’s important to understand the risks posed by unprotected JavaScript code. Answering these security concerns always calls for a security in-depth approach, meaning incorporating source code protection into a robust client-side security strategy.
When it comes to ensuring the maximum level of protection of JavaScript source code, the best answer is to rely on a trustworthy vendor that provides resilient and potent obfuscation, along with runtime protection and a broad range of integrations.
For over 10 years, Jscrambler has been the leading JavaScript obfuscation and protection technology. With a strong investment in R&D, Jscrambler has introduced most of the innovative features and patents when it comes to JavaScript protection, including features like self-healing, self-defending, and control flow flattening.
After over 700,000 protected code builds and recognition by advisory firms like Gartner, Jscrambler is the trusted choice of the Fortune 500 and thousands of companies globally.
JavaScript Obfuscation and Jscrambler
Jscrambler’s Code Integrity makes your JavaScript code resilient, so it can’t be read, copied, tampered with, or reused.
Every version of code you deploy is automatically protected on every screen. It’s that simple.
Feel free to try all Jscrambler features with a free trial or book a demo with our client-side security experts.
Jscrambler
The leader in client-side Web security. With Jscrambler, JavaScript applications become self-defensive and capable of detecting and blocking client-side attacks like Magecart.
View All ArticlesMust read next
Beyond Obfuscation: JavaScript Protection and In-Depth Security
JavaScript protection is much more than obfuscation. With resilient obfuscation and runtime protection, you can prevent serious client-side attacks.
June 17, 2020 | By Jscrambler | 5 min read
Protecting JavaScript Source Code Using Obfuscation - Facts and Fiction
This will be the very first post in this blog. JScrambler exists since 2010 and it was about time we have a blog.
August 5, 2013 | By Jscrambler | 1 min read
Understanding JavaScript Obfuscation [INFOGRAPHIC]
JavaScript obfuscation transforms the source code into something unintelligible while preserving its original functionality. Here's a useful infographic.
November 3, 2020 | By Jscrambler | 1 min read
